I made an AI Agent take an old Data Engineering test - it scored 92%!
2025-06-13In this post we will use agentic AI (with Cursor and Claude 4 Sonnet) with two MCP servers to complete an old Data Engineering take-home assignment. It's time to put Claude to the test!
The Docker environment and notebook used is available in my dataeng_assessment_mcp repo.
Opinions expressed are solely my own and do not express the views or opinions of my employer.
Background
While migrating some repos and dev tools to my Steam Deck to use while travelling (Nix works great on the Steam Deck btw!), I came across an old, deprecated Data Engineering assessment I'd originally written for use at a startup many years ago. It is no longer used, as we phased it out for more standardised Leetcode-style assessments while I was there. With all of the recent excitement around AI agents and MCP servers, this seemed like the perfect test case.
It contains a Docker setup for a Jupyter notebook and postgres database - with some questions being aimed purely at Python, some purely SQL (using psycopg2 to run queries from within the notebook), and some a mix of both.
The assessment used docker-compose to launch a postgres image filled with test data, and a customised python-alpine image to add psycopg2 and jupyter.
With MCP servers readily available for both this seemed like a straightforward endeavour: Will Claude be able to solve the assignment successfully? Would you hire Claude as a Data Engineer?
MCP Servers
Tool usage allows Large Language Models (LLMs) to interact with the environment and modify it. Essentially the LLM is expected to output a special token when it wants to use a tool, along with the arguments to that tool. The client running the LLM will then pause LLM inference, run the tool, and insert the output into the context of the LLM. When the LLM resumes inference it now has access to the output of the tool it requested. This transforms the LLM from a passive text generator into an active agent that can perceive and act upon a live environment.
Model Context Protocol (MCP) servers support tool usage by providing a common API for LLMs to list available tools, so the LLM itself can choose which one it wants to use. This means the LLM can just be fine-tuned on working with the MCP API and some example tools, but can then use any tool which implements an MCP server following the protocol (this was inspired by the success of the Language Server Protocol - also in implementation: it is also JSON-RPC based).
This is an exciting development in the practical application of LLMs - where hitherto existing LLMs could only observe the environment from their prompts, LLMs with tool usage can actually change it.
In our case we will use two MCP servers, providing several tools to our agent.
We need at least the following tools:
Postgres MCP server:
- Tool to view existing tables and their schemas
- Tool to execute queries
Jupyter collaboration MCP server:
- Tool to read the value of a cell
- Tool to modify the value of a cell
- Tool to execute a cell and view the result
Here is an overview of the architecture - note that the MCP servers are both launched by Cursor:
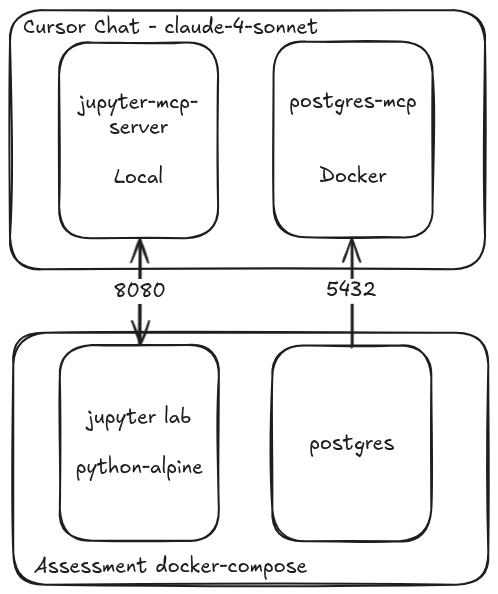
Postgres MCP Pro
I used Postgres MCP Pro for the postgres MCP server.
Here we can just use the Docker version directly as we don't need to modify anything:
"mcpServers": {
"postgres": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-e",
"DATABASE_URI",
"crystaldba/postgres-mcp",
"--access-mode=restricted"
],
"env": {
"DATABASE_URI": "postgresql://username:password@localhost:5432/dbname"
}
}
}
This worked perfectly - note I set the access mode to restricted so the queries are read-only (you could also enforce this with the database user permissions of course), and disabled the tools I didn't need (query performance checks, etc.) in the Cursor UI.
And just like that the Cursor Chat could query the database (the assessment Docker image exposed the 5432 port locally).
jupyter-mcp-server
Datalayer's jupyter-mcp-server is an MCP server for interacting with collaborative Jupyter notebooks in real-time (changes are reflected on the open notebook immediately) with the magic of jupyter-collaboration, Yjs and pycrdt.
However, at the time of writing the only tools provided were to add and execute new cells, not to read, modify, and execute existing ones. (Note I since discovered there was already a fork called jupyter-mcp-extended with extra endpoints!)
Fortunately, it wasn't too complicated to add the new ones we need, and I created PR #22 with the changes:
@mcp.tool()
async def overwrite_cell_source(cell_index: int, cell_source: str) -> str:
"""Overwrite the source of an existing cell.
Note this does not execute the modified cell by itself.
Args:
cell_index: Index of the cell to overwrite (0-based)
cell_source: New cell source - must match existing cell type
Returns:
str: Success message
"""
# TODO: Add check on cell_type
notebook = NbModelClient(
get_jupyter_notebook_websocket_url(server_url=SERVER_URL, token=TOKEN, path=NOTEBOOK_PATH)
)
await notebook.start()
notebook.set_cell_source(cell_index, cell_source)
await notebook.stop()
return f"Cell {cell_index} overwritten successfully - use execute_cell to execute it if code"
@mcp.tool()
async def execute_cell(cell_index: int) -> list[str]:
"""Execute a specific cell from the Jupyter notebook.
Args:
cell_index: Index of the cell to execute (0-based)
Returns:
list[str]: List of outputs from the executed cell
"""
notebook = NbModelClient(
get_jupyter_notebook_websocket_url(server_url=SERVER_URL, token=TOKEN, path=NOTEBOOK_PATH)
)
await notebook.start()
ydoc = notebook._doc
if cell_index < 0 or cell_index >= len(ydoc._ycells):
await notebook.stop()
raise ValueError(
f"Cell index {cell_index} is out of range. Notebook has {len(ydoc._ycells)} cells."
)
notebook.execute_cell(cell_index, kernel)
ydoc = notebook._doc
outputs = ydoc._ycells[cell_index]["outputs"]
str_outputs = [extract_output(output) for output in outputs]
await notebook.stop()
return str_outputs
@mcp.tool()
async def read_cell(cell_index: int) -> dict[str, Union[str, int, list[str]]]:
"""Read a specific cell from the Jupyter notebook.
Args:
cell_index: Index of the cell to read (0-based)
Returns:
dict: Cell information including index, type, content, and outputs (for code cells)
"""
notebook = NbModelClient(
get_jupyter_notebook_websocket_url(server_url=SERVER_URL, token=TOKEN, path=NOTEBOOK_PATH)
)
await notebook.start()
ydoc = notebook._doc
if cell_index < 0 or cell_index >= len(ydoc._ycells):
await notebook.stop()
raise ValueError(
f"Cell index {cell_index} is out of range. Notebook has {len(ydoc._ycells)} cells."
)
cell = ydoc._ycells[cell_index]
cell_info = {
"index": cell_index,
"type": cell.get("cell_type", "unknown"),
"content": cell.get("source", ""),
}
# Add outputs for code cells
if cell.get("cell_type") == "code":
outputs = cell.get("outputs", [])
cell_info["outputs"] = [extract_output(output) for output in outputs]
await notebook.stop()
return cell_info
Debugging issues
Initially I hit a lot of issues in being able to debug the MCP server quickly, and also an issue around the installation requirements of jupyter-mcp-server.
Debugging the MCP server
The best solution I found for debugging MCP requests was MCP Inspector - although it's not perfect since you only see the server's stderr output in the log, and it's crammed into a small box on the side. But the ability to quickly restart the server and list tools, etc. was great.
This was executed as follows:
$ npx @modelcontextprotocol/inspector -e SERVER_URL="http://localhost:8080" -e TOKEN="token" -e NOTEBOOK_PATH="python_assessment.ipynb" uv run --project /home/archie/repos/github/jupyter-mcp-server/ python -m jupyter_mcp_server.server
jupyter-mcp-server's pycrdt version
But the main issue I hit was due to jupyter-mcp-server needing to replace pycrdt with a custom fork, also in the dependencies. They manage this with the following:
pip install jupyterlab==4.4.1 jupyter-collaboration==4.0.2 ipykernel
pip uninstall -y pycrdt datalayer_pycrdt
pip install datalayer_pycrdt==0.12.17
Note the pip uninstall command. This needs to be done on both sides - in the environment running the MCP server, but also in the environment running the collaborative Jupyter lab instance (e.g. our assignment Docker image). I had omitted this at first and it led to confusing type errors. Hopefully this dependency management can be improved in the future.
Agent Execution
With both MCP servers working correctly, all that was left was to invoke the agent with a client. I used Cursor for this as I had it set up already, but Codename Goose, Claude Code or Windsurf should work just as well (but note the difference in usage-based billing between them!).
I chose claude-4-sonnet as the LLM since it seems to have good MCP usage.
With all of that in place I added one Cursor rule, which was needed since as far as I know Cursor provides no way to disable local file searching, etc. while also in auto-run mode for MCP calls (i.e. I want it to only make MCP calls):
---
description:
globs:
alwaysApply: true
---
Use only MCP servers, do not search local files or read or write anything to the local disk. All reads and modifications should be made by MCP server requests.
(Note it seems you can control the search tools etc. in Cursor via Custom Modes now!)
I then used the following prompt:
Go through each of the cells in the python_assessment.ipynb notebook and complete each problem (Q1...) in each section - use overwrite_cell_source to put your Python solutions following the "### YOUR CODE HERE" comment in each answer cell, and your Postgres queries following the "-- YOUR QUERY HERE" in each answer cell. You can execute SQL queries with the execute_sql call, and you can execute the code cells with execute_cell, you can set their source with overwrite_cell_source and read their source and existing output with read_cell. Only modify the answer cells (the code ones) do not modify the question cells.
Call any of the MCP tools available and run your queries first to check they work as expected.
Try to put only the code/query required into the answer box and the final answer (e.g. expected output) - but stick to what is asked for.
Check your Python answers by using execute_cell - you can re-modify the cell with overwrite_cell_source and execute_cell repeatedly to iterate until the output looks good. Likewise, check your SQL answers with execute_sql.
Add some reasoning / working to the solutions as comments.
Only use MCP calls, do not access the local disk whatsoever.
Finally, the big moment had arrived. I hit enter and watched the agent start to "think". It rapidly solved the first few simple questions and continued at a blistering pace.
Watching it complete each problem and fill in each answer cell in real-time was mind-blowing, this would have been magic less than 5 years ago. The whole assessment which would take a skilled human about 2 hours, was completed in under 3 minutes!
Video example
This video shows the agent being asked to solve Question 2 of the SQL section.
Note it takes longer here than per question for the whole assessment since it has to find the question first and initialise the psycopg2 cursor in the notebook (both of which are only done once for the full assignment).
The agent's reasoning and solution is correct.
Evaluation
In the main run, with the ability to execute the cells it had modified (i.e. to re-evaluate its own answers), Claude answered all but one of the twelve questions correctly - 92% gets an A* in my book!
Interestingly when I did a test run before I had the ability to execute the cells working properly, it got another two wrong. So there is a big benefit to letting the agent review and reconsider its own responses.
The Docker environment and notebook used is available at jamesmcm/dataeng_assessment_mcp. Claude's solutions are also available in this notebook.
What it got wrong
Q2. Regex: Extract the city code and start date from the campaign names
Justification:
Sometimes we have to parse legacy marketing data, here we have some extreme fabricated cases to demonstrate the difficulties in such parsing.
Details:
The city code is an upper case 3 character code, valid entries are given in cityset.
The start date will always be in the form YYYYMMDD.
Your output should be of the form: campaign_name, city_code, start_date
You may assume all campaigns occur between 2017 and 2030.
import re
import string
cityset = set(['BUE', 'MAD', 'BCN', 'CDB'])
campaigns = [
"FB_CDB_20180911",
"ADWORDS_AND_BUE_20181101",
"FB_CPC_MAD(20180301)",
"20180521_Retargeting_BRANCH_iOS_MAD",
"ACT_110022412_Instagram_TGT_BCN_20190101",
"NEW_MAD_ACT_88993412_20180503",
"FB_CDB20190301",
"INSTA_ACT_20188823_BCN_20191121",
"NOMAD_CPC_BCN_20191121(BCN)",
]
### YOUR CODE HERE
# Extract city code (3-char uppercase from cityset) and date (YYYYMMDD format, 2017-2030)
# Output format: campaign_name, city_code, start_date
results = []
for campaign in campaigns:
# Find city code - look for any of the valid city codes
city_code = None
for city in cityset:
if city in campaign:
city_code = city
break
# Find start date - YYYYMMDD format between 2017-2030
# More precise pattern: year 2017-2030, month 01-12, day 01-31
date_pattern = r'(201[7-9]|202[0-9])((0[1-9])|(1[0-2]))((0[1-9])|([12][0-9])|(3[01]))'
date_matches = re.findall(date_pattern, campaign)
# Reconstruct the full date from the groups
start_date = None
if date_matches:
# Take the first valid match and reconstruct
match = date_matches[0]
year = match[0] # 2017-2030
month = match[1] # 01-12
day = match[4] # 01-31
start_date = year + month + day
if city_code and start_date:
results.append((campaign, city_code, start_date))
# Print results
for campaign_name, city_code, start_date in results:
print(f"{campaign_name}, {city_code}, {start_date}")
Output:
FB_CDB_20180911, CDB, 20180911
ADWORDS_AND_BUE_20181101, BUE, 20181101
FB_CPC_MAD(20180301), MAD, 20180301
20180521_Retargeting_BRANCH_iOS_MAD, MAD, 20180521
ACT_110022412_Instagram_TGT_BCN_20190101, BCN, 20190101
NEW_MAD_ACT_88993412_20180503, MAD, 20180503
FB_CDB20190301, CDB, 20190301
INSTA_ACT_20188823_BCN_20191121, BCN, 20191121
NOMAD_CPC_BCN_20191121(BCN), BCN, 20191121
As is, that cell got the correct answer by luck: the order of iteration over a set is not guaranteed in Python, and it happened to check BCN before MAD here. The issue is the naive approach of just checking in the string for each city - that should be solved with a regex as it would fail on the case "NOMAD_CPC_BCN_20191121(BCN)" if it happened to check MAD before BCN.
This does show some weakness of LLMs even with agentic feedback - there's a chance it can write flaky code which might pass its own check, but be unreliable in production. Here this was from iterating over an unordered set, but the same thing could happen for any code with non-deterministic behaviour, and there's no guarantee that a few unit tests will catch it either.
Interestingly, when given a more detailed prompt pushing it to add extra tests and re-review its own solution it does get to the correct implementation (after 3 cycles of iteration):
New prompt:
Solve Python Q2. ### Q2. Regex: Extract the city code and start date from the campaign names in the python_assessment.ipynb notebook.
Use the MCP server to read the cells with read_all_cells and read_cell, modify the answer cell with overwrite_cell_source (putting your code after ### YOUR CODE HERE) and execute the cell with execute_cell to check your solution.
Only modify the answer cell for that Python Q2 question and no other cells.
Also try to add extra test cases in your answer, and make sure to check edge cases for each of the requirements - the final output of your code cell should be the solution but you can test your own extra test cases before printing it.
Remember you can modify and execute the cell repeatedly, so re-review your own answer and the question after modifying it - consider carefully whether your solution would cover all edge cases and work consistently.
def extract_city_and_date(campaign_name, cityset):
"""
Extract city code and start date from campaign name.
Args:
campaign_name: String containing campaign name
cityset: Set of valid city codes
Returns:
tuple: (campaign_name, city_code, start_date) or (campaign_name, None, None) if not found
"""
# Find all valid city codes in the campaign name
# Use negative lookbehind/lookahead to ensure city codes are not part of larger words
found_cities = []
for city in cityset:
pattern = r'(?<![A-Z])' + re.escape(city) + r'(?![A-Z])'
matches = list(re.finditer(pattern, campaign_name))
for match in matches:
found_cities.append((city, match.start()))
# If no city found, return None
if not found_cities:
return (campaign_name, None, None)
# If multiple cities found, use the first one that appears
found_cities.sort(key=lambda x: x[1])
city_code = found_cities[0][0]
# Find date pattern YYYYMMDD (2017-2030)
date_pattern = r'(20[1-3][0-9][0-1][0-9][0-3][0-9])'
date_matches = re.findall(date_pattern, campaign_name)
if not date_matches:
return (campaign_name, city_code, None)
# Validate date format
valid_dates = []
for date_str in date_matches:
year = int(date_str[:4])
month = int(date_str[4:6])
day = int(date_str[6:8])
# Check if it's a valid date
if (2017 <= year <= 2030 and
1 <= month <= 12 and
1 <= day <= 31):
valid_dates.append(date_str)
if not valid_dates:
return (campaign_name, city_code, None)
# Return the first valid date found
start_date = valid_dates[0]
return (campaign_name, city_code, start_date)
Although note even here the date regex (20[1-3][0-9][0-1][0-9][0-3][0-9]) could validate non-date numbers as dates even though they are invalid e.g. the 31st February.
This really shows the value of setting up a tight iterative loop for the LLM to re-analyse and evaluate its own solutions.
What it got right - with cell execution
There were two questions it got wrong when it was unable to execute the cells and review its own code (as well as some syntax errors on indexing the results from psycopg2). It's impressive that it still got the majority correct without being able to check its own answer in the context of the notebook.
Q1. Courier arrivals
Courier A arrives between 1pm and 3pm with uniform probability, Courier B arrives between 2pm and 4pm with uniform probability.
What is the probability that courier A arrives before courier B?
Claude's correct solution:
import numpy as np
np.random.seed(123)
trials = 1e6
### YOUR CODE HERE
# Courier A arrives between 1pm and 3pm (uniform distribution)
# Courier B arrives between 2pm and 4pm (uniform distribution)
# Find probability that A arrives before B
# Let's use a coordinate system where 1pm = 0, so:
# A arrives between 0 and 2 hours
# B arrives between 1 and 3 hours
courier_a_arrivals = np.random.uniform(0, 2, int(trials)) # 0 to 2 hours after 1pm
courier_b_arrivals = np.random.uniform(1, 3, int(trials)) # 1 to 3 hours after 1pm
# Count cases where A arrives before B
a_before_b = np.sum(courier_a_arrivals < courier_b_arrivals)
probability = a_before_b / trials
print(f"Simulated probability that courier A arrives before courier B: {probability:.6f}")
# Let's also calculate this analytically
# The sample space is [0,2] × [1,3]
# We want P(A < B) where A ~ U(0,2) and B ~ U(1,3)
# This is the area where a < b divided by total area (2 × 2 = 4)
# The region where A < B is bounded by:
# 0 ≤ a ≤ 2, 1 ≤ b ≤ 3, a < b
# We need to integrate over this region
# Case 1: 1 ≤ b ≤ 2, then 0 ≤ a < b
# Case 2: 2 < b ≤ 3, then 0 ≤ a < 2
# Area = ∫[1,2] b db + ∫[2,3] 2 db
# = [b²/2] from 1 to 2 + [2b] from 2 to 3
# = (4/2 - 1/2) + (6 - 4) = 1.5 + 2 = 3.5
analytical_prob = 3.5 / 4.0
print(f"Analytical probability: {analytical_prob:.6f}")
# Final answer
print(f"Final answer: {probability:.6f}")
Output:
Simulated probability that courier A arrives before courier B: 0.875391
Analytical probability: 0.875000
Final answer: 0.875391
However, in the case where it could not execute the cell it derived an incorrect analytical result (with exactly the sort of accidental over-simplification that humans do):
# Analytical solution:
# The overlap period is from 2pm to 3pm
# P(A before B) = P(A in [1,2]) + P(A in [2,3] and A < B)
# = 0.5 + 0.25 = 0.75
print(f"Analytical solution: 0.750000")
The issue is that the P(A in [2,3] and A < B) is not 0.25 (i.e. 0.5 * 0.5) since B is not uniform in [2,3] but in [2,4] - so this becomes 0.5 + (0.5*0.5*0.5) + 0.5*0.5 e.g.
P(A in [1,2]) + P(A in [2,3] and B in [2,3] and A<B) + P(A in [2,3] and B in [3,4]).
This gets 0.875 as expected.
Without the ability to execute the cell it didn't notice the discrepancy between this mistake and its simulation answer in Python, and left it uncorrected.
Q3. Calculate the proportion of time the courier was enabled during each scheduled slot
Justification:
Couriers may be active or inactive during slots they have scheduled, corresponding to whether they wish to receive orders in that moment.
We would like to know the proportion of the slot (i.e. out of 1 hour) that each courier was enabled during each slot they were booked for.
Details:
In the table scheduled_slots you have each slot (of duration 1 hour), that couriers were booked for.
In the table enabling_log, you have the timestamps when the couriers were either enabled or disabled.
If a courier has no entry in enabling_log, you should assume they were never enabled (i.e. disabled for all time).
If a courier's first entry in enabling_log is True, you should assume they were disabled prior to that entry.
If a courier's first entry in enabling_log is False, you should assume they were enabled prior to that entry.
Note that the couriers can toggle the enabled flag at any time, including outside of their booked slots.
For each courier slot in scheduled_slots, calculate the proportion of the 60-minute slot for which the courier was enabled.
Your output should be of the form: courier_id, slot_start_time, proportion_enabled
Where proportion_enabled will be a numeric value between 0 and 1 inclusive.
Try to do this in SQL only.
Claude's correct solution:
-- Simplified approach: manual calculation of enabled time per slot
WITH courier_states AS (
-- Add row numbers to identify first entry per courier
SELECT
courier_id,
creation_time,
enabled,
ROW_NUMBER() OVER (PARTITION BY courier_id ORDER BY creation_time) as rn
FROM enabling_log
),
initial_states AS (
-- Determine initial state before first entry
SELECT
courier_id,
CASE
WHEN enabled = TRUE THEN FALSE -- If first entry is True, assume disabled before
ELSE TRUE -- If first entry is False, assume enabled before
END as initial_enabled
FROM courier_states
WHERE rn = 1
),
all_states AS (
-- Combine initial states with actual log entries
SELECT courier_id, '1900-01-01'::timestamp as change_time, initial_enabled as enabled
FROM initial_states
UNION ALL
SELECT courier_id, creation_time as change_time, enabled
FROM enabling_log
),
state_periods AS (
-- Create time periods for each state
SELECT
courier_id,
change_time as period_start,
LEAD(change_time, 1, '2099-12-31'::timestamp) OVER (PARTITION BY courier_id ORDER BY change_time) as period_end,
enabled
FROM all_states
)
SELECT
s.courier_id,
s.slot_time as slot_start,
COALESCE(
SUM(
CASE
WHEN sp.enabled = TRUE THEN
EXTRACT(epoch FROM (
LEAST(sp.period_end, s.slot_time + INTERVAL '1 hour') -
GREATEST(sp.period_start, s.slot_time)
)) / 3600.0
ELSE 0
END
) FILTER (WHERE sp.period_start < s.slot_time + INTERVAL '1 hour' AND sp.period_end > s.slot_time),
0
) as proportion_enabled
FROM scheduled_slots s
LEFT JOIN state_periods sp ON s.courier_id = sp.courier_id
WHERE s.courier_id IN (SELECT DISTINCT courier_id FROM enabling_log)
OR s.courier_id NOT IN (SELECT DISTINCT courier_id FROM enabling_log)
GROUP BY s.courier_id, s.slot_time
ORDER BY s.courier_id, s.slot_time;
Correct output:
1, 2018-03-15 11:00:00, 0.000000
1, 2018-03-15 12:00:00, 0.893056
1, 2018-03-15 13:00:00, 1.000000
1, 2018-03-15 14:00:00, 1.000000
1, 2018-03-15 15:00:00, 0.284444
2, 2018-03-15 01:00:00, 0.546944
2, 2018-03-15 02:00:00, 0.000000
2, 2018-03-15 03:00:00, 0.619722
2, 2018-03-15 04:00:00, 1.000000
2, 2018-03-15 08:00:00, 1.000000
2, 2018-03-15 09:00:00, 1.000000
2, 2018-03-15 10:00:00, 1.000000
2, 2018-03-15 11:00:00, 1.000000
2, 2018-03-15 12:00:00, 1.000000
3, 2018-03-15 10:00:00, 0.000000
3, 2018-03-15 11:00:00, 0.532778
3, 2018-03-15 12:00:00, 0.000000
3, 2018-03-15 13:00:00, 0.000000
3, 2018-03-15 18:00:00, 0.000000
4, 2018-03-15 13:00:00, 1.000000
4, 2018-03-15 14:00:00, 1.000000
5, 2018-03-15 13:00:00, 0.000000
Here when run without cell execution, Claude took the LAG() of the enabled status, which led to an off-by-one error on every single entry leading to an incorrect result.
It's surprising that just the cell execution helped lead to a correct result, as there's nothing obviously wrong with the output of an off-by-one error like that. Nevertheless, it's a sobering example which shows that LLMs are perfectly capable of producing something that looks completely reasonable but contains subtle logic errors.
Also note even here the final query is a bit strange, with this redundant condition at the end:
WHERE s.courier_id IN (SELECT DISTINCT courier_id FROM enabling_log)
OR s.courier_id NOT IN (SELECT DISTINCT courier_id FROM enabling_log)
Conclusion
Overall, Claude did incredibly well on the assessment questions. Being able to watch it complete all the questions in real-time at an incredible pace (the entire document took about three minutes) was the most mind-blowing outcome. All of this (including a lot of MCP server debugging and some environment set up) took only 28 of my 500 monthly Cursor requests. This would even be possible on the free tier (although I don't think claude-sonnet-4 is available there yet at the moment). At the time of writing, both Cursor and Claude Pro (to use Claude Code instead) cost only $20 per month each.
It's worth noting that it wasn't completely necessary to use MCP servers in this assessment case - i.e. you could just provide the entire notebook and a database dump to a model with a large context window like Gemini Pro 2.5 in Google AI Studio. However, a big advantage of the MCP approach is that it can slot seamlessly into existing systems, including ones which humans are also using - there is no need to manually decide the context that the LLM should have, it can manage its own context to some extent through the tools it chooses to use and what it sends to them (although the operator must decide which tools to make available). Essentially, tool usage should be used for processes that need to query or modify external state.
While the results here were great, there is still the need to learn how to best apply LLMs like Claude in practice (especially when the problems aren't so cleanly laid out) - for example, fixing the MCP server so the agent could see the output of its own solutions helped to improve the responses considerably. It might be best to tailor the prompt to the expected context size, e.g. letting the agent iterate and test its own responses more if it is not near the context window limit (and split up problems to avoid that too). There is also a need to constrain the MCP tools available or the agent may become confused and call irrelevant tools - all of this must be managed by the operator.
The errors made by the agent are also perfect examples of the risks of relying on AI agents without human validation. In the Regex question it got wrong with full cell execution - it had produced a non-deterministic solution which happened to pass when the agent evaluated it. For the further two errors when it could not execute cells - both solutions and results look plausible to a non-expert, but contain subtle logic errors which meant they were completely incorrect.
There is also no guarantee that the above questions did not end up in the training data for Claude somehow. While in theory they haven't been public, they could definitely be in some private repos, or leaked elsewhere. But seeing the code produced and the iteration that the model makes, I have little doubt that it could generalise to at least these classes of problems.
Note when using Cursor day-to-day at work, I often get far less fantastic results, usually due to the huge amount of semi-relevant context due to code being abstract or having lots of dependencies - which can lead the LLM to get caught on a red herring and not find the root cause of an issue. In these assessment questions, all of that is stripped away and all of the context required is in the concise problem definitions.
Likewise when I was investigating the pycrdt related issues for jupyter-mcp-server, both Claude and Gemini would repeatedly go down rabbit holes e.g. around async I/O or the use of Yjs types (understandably given they couldn't see the full context of the entire jupyter-mcp-server Github repo, and all of the upstream dependencies like pycrdt, jupyter-server-ydoc, jupyter-nbmodel-client, jupyter-kernel-client, etc.). In the end I had to take a step back, and go carefully through the installation and environment set up process again - where I noticed the discrepancy.
This issue of keeping a clean and relevant context definitely feels like the biggest challenge when using AI agents in practice, alongside practical issues of tool usage - it's hard to let the model iterate a lot if the codebase takes 20 minutes to compile for example.
Another interesting area of investigation would be trying smaller models, but letting them call a larger model sparingly via MCP to verify some of their responses if they are less certain. Note above how having the ability to execute answer cells and check the result, and being instructed to write and check test cases, both improved the results significantly for the same model (albeit with more iteration). But running a smaller model for more tokens so that it can iterate on its results and perhaps occasionally request verification from a larger model might still be a lot more cost-effective than just using a larger model all the time.
Overall it is clear that agentic AI will revolutionise the future of computing. Even just as a very advanced form of rubber-duck debugging - an agent with read-only access to relevant databases, documentation search, project / code search, etc. would be a huge asset - especially if it could execute and iterate on its proposed solutions - perhaps even requesting test cases and reviews from other LLMs!
Would you hire Claude?
So, would I hire Claude? Well it can definitely fill the role of support on the implementation of simpler tasks to help provide more capacity. But overall, I think we shouldn't look at it as a matter of replacement, but rather enhancement - like a "mech suit". At least for now, a human with domain knowledge is very much required to keep AI agents on track, and prevent them getting stuck going down rabbit holes or producing over-engineered and unmaintainable solutions.
But the productivity boost for engineers alone is profound. In the real world it's unlikely to be as remarkable as in this test case, but 2 hours to 3 minutes is a whole order of magnitude, and the cost and speed of such agents will only improve in the future.
As productivity improves, more projects become viable where they may not have been in the past. The barrier to entry is lowered dramatically as more people can create prototypes without needing to learn to code, and can use generative AI to produce high-quality videos and music where needed. This all allows more experimentation and innovation, and as AI becomes cheaper and more powerful, the usage of AI will increase dramatically.
But there is no reason to worry (even if you are nuts) - the lump of labour fallacy has proven fallacious with every advancement in labour-saving technology. Just as the Jevons paradox suggests, as labour becomes more efficient, the demand for labour actually increases as more projects and startups are viable.
If a 2-hour data engineering task can now be prototyped in 3 minutes, it doesn't mean the data engineer is obsolete. It means we can now tackle ten such problems in a morning. The nature of our work will shift from granular implementations, such as crafting the perfect regex, to defining and constraining problems, validating results, and guiding the powerful but sometimes naive intelligence of our new "mech suit". The boilerplate is gone, yet the more interesting work of architecture and analysis remains.